Agentic Patterns: Elements of Reusable Context-Oriented Determinism 🔗
While not as exhaustive as the title might indicate but aligned with my focus on enforcing as much determinism as possible from any given LLM ala Article let's take a look at exploiting tool using LLMs as a process instead of as a conversation. As I posed in the linked article much of the failures we experience are related to attention and confusion which is the progressive noise we introduce as we try to convince the model to perform an action.
What I describe below are patterns for building A Deterministic Box for Non-Deterministic Engines
Chats are an artifact 🔗
This behavior of progressing the chat with multiple statements to a solution is merely an artifact of pre-tooluse models. So we the humans needed to interact with moving files and integrating code at each step while testing it became natural to turn interactions into long conversations. Ones that eventually degrade into failure loops, while surely someone has told you to just keep clearing your context and start over.
Since the evolution of tools like functiongemma which provides trainable, simple function calling on commodity hardware we are on the edge of building decision trees for tool oriented expert systems, but that's a topic for a different day. For now the models we have that are effective tool users are too large to be portable and our contract is still text.
Reduction in variability 🔗
You may recall from math class that you should avoid deriving new values from derived values until you can prove the quality of the procedure. As any instability in accuracy will grow the inaccuracy of outputs. The same is essentially the normal behavior of long running chats. Since model responses can essentially steer (influence) the decisions of the model in the future of the same context window we can fall into a quality trap.
import anthropic
client = anthropic.Anthropic()
messages = []
while True:
# Get input from you
user_input = input("You: ")
# Put your message in the context
messages.append({"role": "user", "content": user_input})
# Send the context to the LLM
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=messages, # Full history sent each time
)
# LLM response
assistant_message = response.content[0].text
# LLM response added to context
messages.append({"role": "assistant", "content": assistant_message})
print(f"Claude: {assistant_message}\n")
# Loop
As this partial example shows if we send 3 messages there will be 3 responses and our context is 6 messages. Each time we send something new the LLM rereads the entire context not just the last message meaning any derived issues that we or the LLMs predictive invariability adds can pollute the quality of the overall decisions made. There are also unseen patterns due to how training is compressed that leads to non-intuitive work and concept replacement for convoluted examples. For example the LLM will be more accurate if there was more reinforcement during deep learning of that topic and it fails faster when exercising in novel space. If you wanna understand this better go read this book: https://sebastianraschka.com/llms-from-scratch/
KISS the LLM 🔗
So the solution is the same as it ever was. Keep things small and focused on a single task. The LLM isn't a person and doesn't think, we are using human language to steer outputs the same way we write function signatures to have enough context to supply information to downstream operations. That doesn't mean we never chat with the bot. It does have a big context window and we can take advantage of that for specific patterns. Plan-Then-Execute Pattern
As discussed we want to keep context focused when we need a long running session. This is the key to plan-then-execute. Coding agents' system prompts have been biased towards creating implementations which like an eager intern jumps the gun and starts building before understanding. When this happens we find ourselves immediately refactoring the wrong idea. The context becomes polluted with examples of the wrong solution and leads to lower quality outputs.
While some coding agents have a "planning" mode, this is a system prompt hack to try and keep it from producing but I'll admit I have had lower luck because this funnels you towards implementation faster. The solution here is to work with the agent's bias to produce and have it produce research artifacts. It will gladly deep dive into a code-base and provide elegant descriptions of architecture and sequence. This is best performed with a reasoning model.
Kill-Then-Breakdown Pattern 🔗
A sub-step of plan then execute requires context flushing. After we have verified the quality of the research we start fresh and have the next agent, preferably a reasoning model, read that research document and we instruct it to break down the work into tasks and provide a planned implementation to each task. Once again we are working towards the models goals of writing code or producing files and we get small snippets of code associated with each task. The plan and breakdown is a token heavy portion of the work stream but since we keep check-pointing with artifacts written in markdown there is a repeatable retention in value. That said context size does play a part in cost so flushing the context and loading a compacted version of the topic does end up saving some cost over the context exploding and the risk of loss during compaction.
Now Execute (Mr. Meeseeks Pattern) 🔗
While you can use a single reasoning model to go through each task it has broken down and implement it there is a better way. We can ask the reasoning model to act as an orchestrator that spawns sub-agents of cheaper models for each task in the Mr. Meeseeks pattern. The reasoning model starts a simpler model and passes it the task and expected implementation we just broke down and goes to work on it. For simplicity's sake don't run these operations in parallel yet without some considerations to keep multiple agents from overwriting themselves. As each task is marked completed the sub-agent will be killed and a new one with a fresh context is started.
It's important to remember that the orchestrator gets the output from the subagents so if your development environment produces a lot of noise or if your agents aren't clamping their read size you may run into interesting scenarios where you overflow the coding agents memory. The solution here is to run each sub-agent in a new process instead as a task run by the first coding agent. I am sure you can see how this can expand.
Specification-Driven Agent Development Pattern 🔗
Is what we just accomplished. During planning we created a specification from an existing code-base or a set of discussions. Then we captured focused implementation details. Then we did a bunch of tiny implementations. While the more formal nature of spec driven usually stops at the original manifest of "what is this feature going to be" we should take it one step further to actually storing partial facts about implementation. On the consumption side of the coder agent it will be somewhat literal with what it was given but it has to perform integration and resolve writing tests as well as ensure the work fits into existing tests and functionality.
Also given we have this spec we can add extra steps to our workflow. The orchestrator ends up following a very simple workflow and its focus is retained around the same document of compressed knowledge it wrote. This is an important fact because models are specifically expressive, they talk a certain way, which means a model reading what it wrote is less ambiguous than it reading what you wrote. It has enforced patterns from training we can reactivate.
Agent Verifier Pattern (Code Review) 🔗
Since we have all these concrete artifacts regarding code and spec and final implementation we can then as our last step ask a small simple agent to just give us a thumbs up or down on it, essentially a code reviewer. Before we determine something is done we allow a new context to observe just the changes and the spec, if it rejects we spawn a new implementer to try again. Then we spawn a new reviewer and review again until it works.
In practice this interaction looks a little something like this:
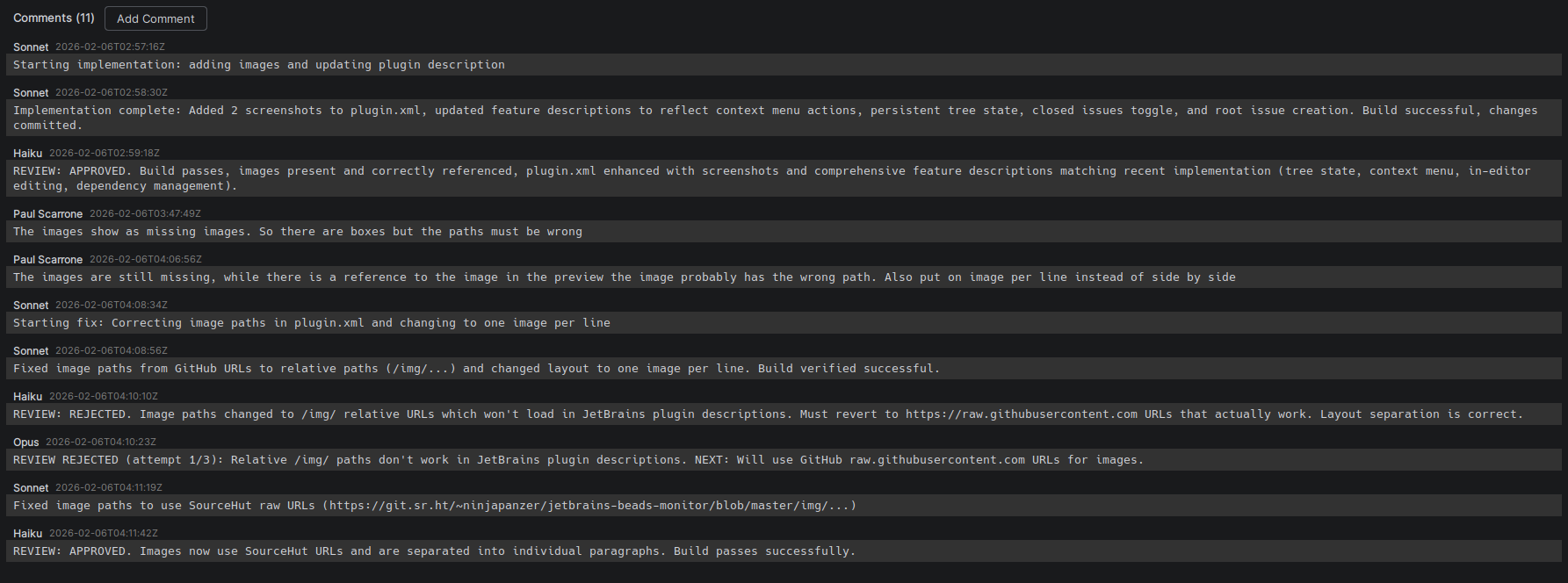
During the end of this task the image to be added wasn't correct and the reviewer failed it causing it to loop.
Prompt Writer Agent Pattern 🔗
So this doesn't work out of the box but it's pretty easy mock up. The next step is to codify what we send during each phase of execution. For this to work we need to be very explicit. Even though the orchestrator knows the workflow it may forget as it handles agent spawning which leads to the workflow rules not being transferred to the sub agents. We are in a derived value degradation problem again.
We have to help the orchestrator by providing it a template of the actions we want each sub-agent to take. It can fill in the gaps with the task. So before it spawns an agent it reviews the workflow and writes the sub-agent prompt to a file. It then tells the sub-agent to read the file and implement. This provides two benefits to accuracy. Since the orchestrating agent has to keep re-reading the template ala RE2 (Read and Re-read prompting) it retains more attention because it keeps getting repeated in the context. Since it then writes the refined prompt for the agent if we crash or context collapses we can immediately recover by reviewing overall task process and the presence of the prompt files. It is in fact highly durable allowing multiple orchestration concurrently if you have the money.
Additionally, the reviewer will get its own prompt written but it can review the coders prompt when checking for spec compliance.
In Practice 🔗
If I align this to Anthropic models:
- Orchestrator -> Opus (Reasoning)
- Implementer -> Sonnet (Competent)
- Reviewer -> Haiku (Simple)
I also don't rely as much on markdown files past the very first phase of planning. I move all context with the exception of sub agent prompts into a graph. For that graph I use beads which while it has its flaws enables an approach I call the "Context Graph Pattern" which I will go into in a bit.
What beads essentially is is Jira or Linear but with a outputs that work better for LLMs. Essentially a command line tool that has a help dialog that outputs markdown instructions, which improves comprehension by the LLM. It's a graph because like any issue tracker issues can form chains and comments.
In the previous picture above this comment stream is from a plugin to interact with my graph visually. It permits me to leave comments for the agents or even rewrite a spec on the fly.
Context Graph Pattern 🔗
Using a tool that allows me to commit context as a focused structure means I get reproducibility and an audit log. Since beads uses issue IDs as commit names the graph extends into the git history. Code and spec and decision tree can all be one artifact without reading all the files. This keeps our context as tight as possible.
Because the graph is mutable if the first attempt was a complete failure I have two choices:
- Provide feedback as a refinement and retry -> Refactor
- Rewrite the spec and have the agent pull the previous changes and start over -> Rewrite
I can continue to iterate this way at a much lower time cost to me as a developer and since the graph is also able to be committed to a repo and shared with other developers they can do the same.
When we enhance a feature we can include the previous changes either by diff review and spec retrieval from the graph or by explicit linking within the graph itself. There is a portion of this structure that lets you act as Product, Project, and Tech Lead for the given outcomes.
Of course no silver bullet, you will end up a developer for some things in the end don't worry. But this can be guided by a concrete context for yourself when you ask the LLM what it thinks went wrong and you get your hands dirty.
Example 🔗
If you wanna see a functional example of this process I have been dog-fooding it for a bit and all the artifacts from the plugin I posted a picture of are over here.
https://git.sr.ht/~ninjapanzer/jetbrains-beads-manager
A majority of this code was written in my absence in a execution loop. This usually gets you about 80% there. I then spend some time filing bug tickets adding clarifications and refinements. There were only 3 actual chat sessions that occurred during integration where I provided some focused behavioral examples and some bulk documentation where it built some new tasks and orchestrated them.
I would call this a mature alpha as it was produced in 1 sitting. Functionality is usable enough that I finished the development only using the plugin. But this isn't showing off If you pull this down and have beads installed you can see my prompts and what an actual context graph looks like.
The point 🔗
Is not to replace humans as the engineers but replace the grunt work. That said the pattern is implied by the use case. If I am building silly tools for myself, who cares what the code really looks like. If I am building functionality I have to rely on, I need to put considerably more agency in the matter. I will still offload the grunt work when possible but it still a practice. I would hope my carpenter would cut a few less corners on my cabinets than their own. It's not that we are lazy it's we exercise our agency in a way that is comfortable for us. What we build for others must be of the highest quality, what we build for ourselves needs to meet the need.
I mean who knows what will happen and if greed will win and our work will be meat base robot pooper-scoopers. Until everyone figures it out get more work done and take a few more coffee breaks.